
點我下載:song_rank2.csv
import pandas as pd
with open('data/song_rank2.csv') as f:
p2 = pd.read_csv(f)
p2

p2.Artist
0 五月天 阿信
1 魏嘉瑩, 魏如昀
2 陳芳語 , 茄子蛋
3 蕭敬騰, 馬佳
4 吳汶芳
5 琳誼 Ring, 許富凱
6 張語噥
7 Ray 黃霆睿
8 飛兒樂團
9 摩登兄弟劉宇寧
10 五月天 阿信
11 五月天 阿信
12 魏嘉瑩, 魏如昀
13 陳芳語 , 茄子蛋
Name: Artist, dtype: object
[0]*14
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[0]*len(p2.Artist)
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
n = len(p2.Artist)
Artist2 = pd.Series([0]*n)
Artist2
0 0
1 0
2 0
3 0
4 0
5 0
6 0
7 0
8 0
9 0
10 0
11 0
12 0
13 0
dtype: int64
p2.insert(5, 'Artist2', Artist2)
p2
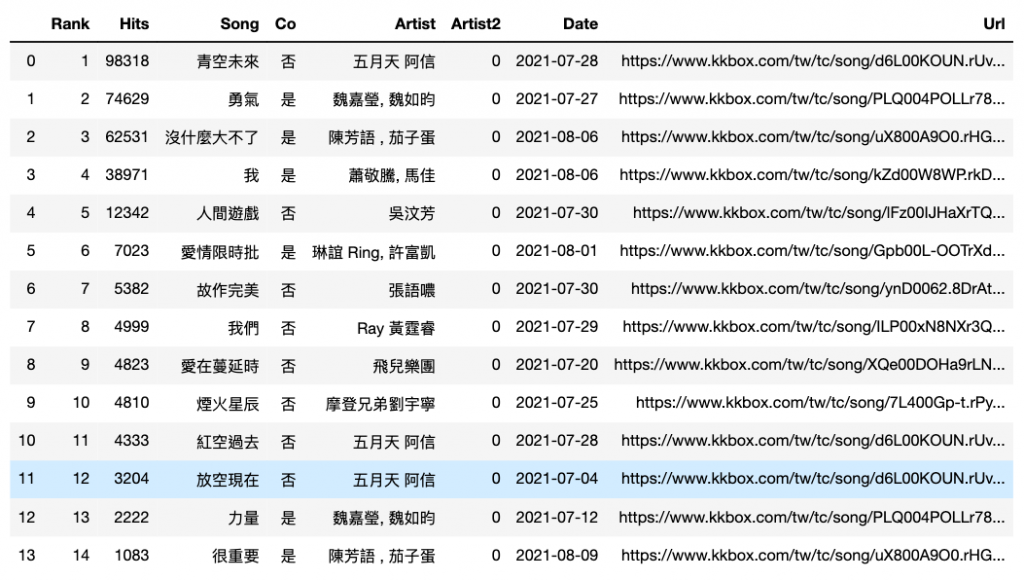
p2.Artist
0 五月天 阿信
1 魏嘉瑩, 魏如昀
2 陳芳語 , 茄子蛋
3 蕭敬騰, 馬佳
4 吳汶芳
5 琳誼 Ring, 許富凱
6 張語噥
7 Ray 黃霆睿
8 飛兒樂團
9 摩登兄弟劉宇寧
10 五月天 阿信
11 五月天 阿信
12 魏嘉瑩, 魏如昀
13 陳芳語 , 茄子蛋
Name: Artist, dtype: object
| Artist |
|---|
| 魏嘉瑩, 魏如昀 |
| Artist1 | Artist2 |
|---|---|
| 魏嘉瑩 | 魏如昀 |
p2.Artist[1]
'魏嘉瑩, 魏如昀'
p2.Artist[1].split(',')
['魏嘉瑩', ' 魏如昀']
p2.Artist[1].split(',')[0]
'魏嘉瑩'
p2.Artist[1].split(',')[1]
' 魏如昀'
p2.Artist[1].split(',')[1].strip()
'魏如昀'
Series.str.split( , expand=True)
p2.Artist.str.split(',', expand=True) # expand=True 分開的東西再創一個欄位
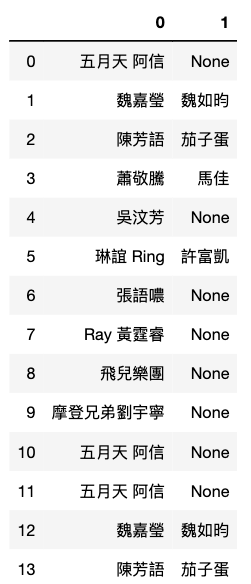
p2.Artist.str.split(',', expand=True)[1]
0 None
1 魏如昀
2 茄子蛋
3 馬佳
4 None
5 許富凱
6 None
7 None
8 None
9 None
10 None
11 None
12 魏如昀
13 茄子蛋
Name: 1, dtype: object
art1 = p2.Artist.str.split(',', expand=True)[0]
art2 = p2.Artist.str.split(',', expand=True)[1]
for i in p2.Artist:
print(i.split(','))
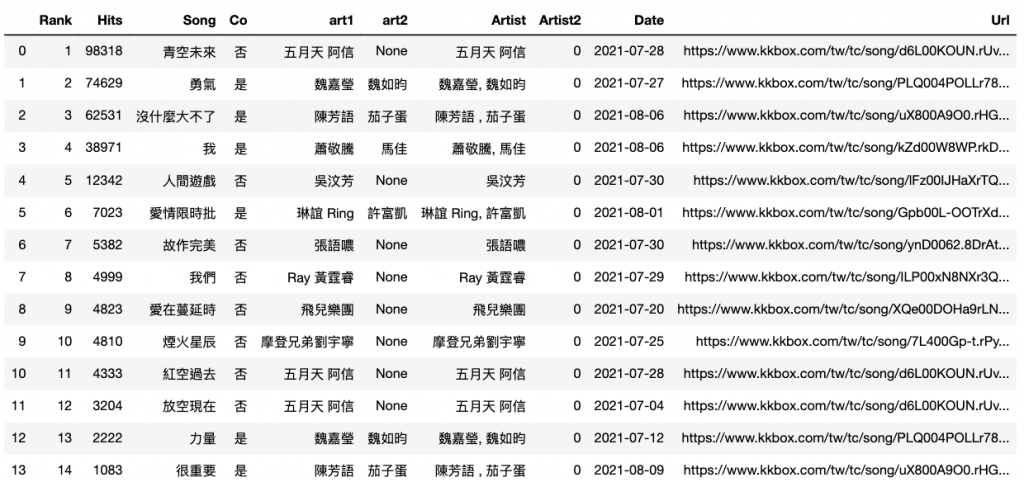
p2.insert(4, 'art1', art1)
p2.insert(5,'art2', art2)
p2
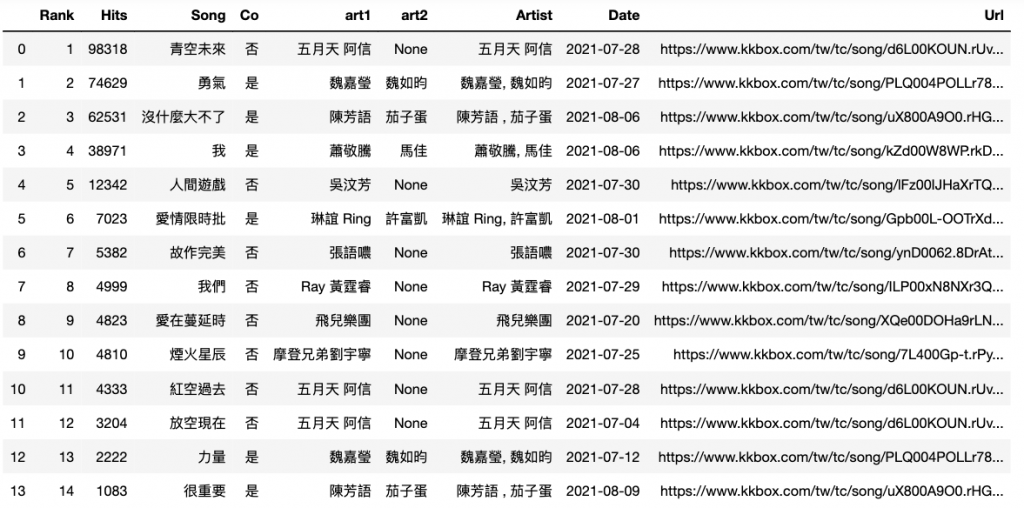
p2 =p2.drop(columns='Artist2')
p2

 iThome鐵人賽
iThome鐵人賽